Cloud Run Jobs with dbt
dbtGCPCloud RunI have been a fan of BigQuery and dbt for a long time and the two of them work well together for me via Github Actions. Not only can I keep my dbt models up-to-date in a Github repo, but I can also launch dbt itself when certain events happen, such as when an updated model is pushed to the repo. But there are downsides to running dbt via Github Actions.
Keeping BigQuery "outside" of Google Cloud Platform means having to download and store service account credentials on Github. In addition to that, the Github runner is probably not really meant for long-running data jobs, even if you use your own runner.
Cloud Run would be a good candidate for running dbt, but having to use an http server just to trigger dbt via a POST or GET request seems like unnecessary overhead. It also feels wrong for a web server to potentially wait several minutes while dbt runs before sending back an http response.
It would be nice to have a service that can run workloads on GCP without the overhead of an http server.
Enter Cloud Run Jobs. This new service essentially allows you to directly execute programs installed in a Docker container. Cloud Run Jobs also come with additional horsepower and much longer timeouts than the standard http-triggered Cloud Run service - up to one hour.
I am happy to report that it's not too hard at all to get this to work. Here's an approach that works for me.
Using my base dbt Docker image that exposes the dbt CLI I also install the gcloud SDK.
# public dbt docker image
FROM mwhitaker/dbt_all:v1.1.0
# install gcloud
RUN apt-get update && \
apt-get install -y curl gnupg apt-transport-https ca-certificates && \
echo "deb [signed-by=/usr/share/keyrings/cloud.google.gpg] http://packages.cloud.google.com/apt cloud-sdk main" | tee -a /etc/apt/sources.list.d/google-cloud-sdk.list && \
curl https://packages.cloud.google.com/apt/doc/apt-key.gpg | apt-key --keyring /usr/share/keyrings/cloud.google.gpg add - && \
apt-get update -y && \
apt-get install google-cloud-sdk -y
COPY entrypoint.sh /entrypoint.sh
ENTRYPOINT [ "/entrypoint.sh" ]Let's take a look at the entrypoint file, which gets copied into the image when it gets built. It expects one positional argument for the dbt command to run, e.g. dbt run. It also pulls my dbt models from a separate repo. That way I can keep those models updated independently of Cloud Run. I then capture both the dbt output and the dbt run output and save those to Cloud Storage. As you can see in the commented-out lines, you could use other gcloud utilities to do other work or trigger other services.
#!/bin/bash
set -o pipefail
if [ $# -eq 0 ]; then
echo "No arguments provided"
exit 1
fi
rm -rf temp_dir
# get the dbt model
git clone --depth 1 https://github.com/mwhitaker/dbt-model-repo.git temp_dir
cd temp_dir
DBT_LOG_FILE=${DBT_LOG_FILE:="dbt_console_output.txt"}
# capture console logs and put in txt file
$1 2>&1 | tee "${DBT_LOG_FILE}"
if [ $? -eq 0 ]
then
echo "Run OK"
echo "DBT run OK" >> "${DBT_LOG_FILE}"
gsutil cp $DBT_LOG_FILE gs://my-dbt-bq-project/folder/$DBT_LOG_FILE
gsutil cp target/run_results.json gs://my-dbt-bq-project/folder/run_results.json
# or other gcloud cli tools
# bq extract
# bq load
# gcloud pubsub
else
echo "Run Failed"
echo "DBT run failed" >> "${DBT_LOG_FILE}"
gsutil cp $DBT_LOG_FILE gs://my-dbt-bq-project/folder/$DBT_LOG_FILE
exit 1
fiTo build this image just takes another simple set of gcloud commands, which I got from these demos:
#!/bin/bash
gcloud config set account you@example.com
export PROJECT_ID=my-dbt-bq-project
# Choose europe-west9 if REGION is not defined.
export REGION=${REGION:=europe-west9}
echo "Configure your local gcloud to use your project and a region to use for Cloud Run"
gcloud config set project ${PROJECT_ID}
gcloud config set run/region ${REGION}
echo "Enable required services"
gcloud services enable artifactregistry.googleapis.com run.googleapis.com cloudbuild.googleapis.com
echo "Create a new Artifact Registry container repository"
gcloud artifacts repositories create dbt-images --repository-format=docker --location=${REGION}
echo "Build this repository into a container image"
gcloud builds submit -t europe-west9-docker.pkg.dev/${PROJECT_ID}/dbt-images/dbt-comboYou can now create the actual Cloud Run job:
# Cloud Run Jobs only in Paris for now. Vive la différence.
gcloud beta run jobs create dbt-run6 \
--args="dbt run --profiles-dir ." \
--image europe-west9-docker.pkg.dev/${PROJECT_ID}/dbt-images/dbt-combo:latest \
--service-account dbt-user@${PROJECT_ID}.iam.gserviceaccount.comYou can also provide arguments to specify the amount of RAM or CPUs you want to allocate, but the key bit here is the service account flag. Cloud Run Jobs run within the context of that service account (so it obviously needs the right BigQuery scopes and whichever other GCP services you want to use, such as gsutil for Cloud Storage). I really like that all the auth stuff is handled automatically for me.
After you create the job you have to execute it. Again you can use gcloud or set up a recurring schedule via Cloud Scheduler.
gcloud beta run jobs execute dbt-run6You get great logging in the GCP console
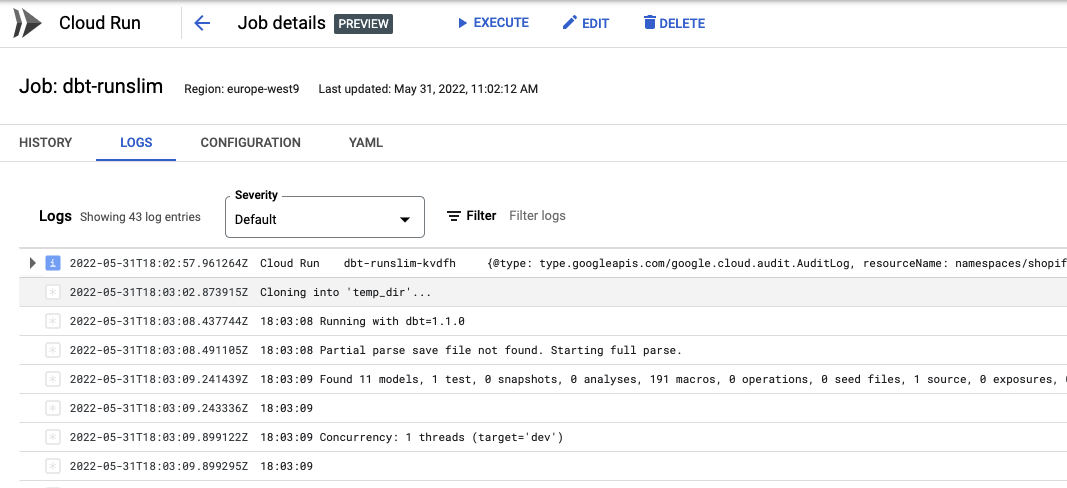
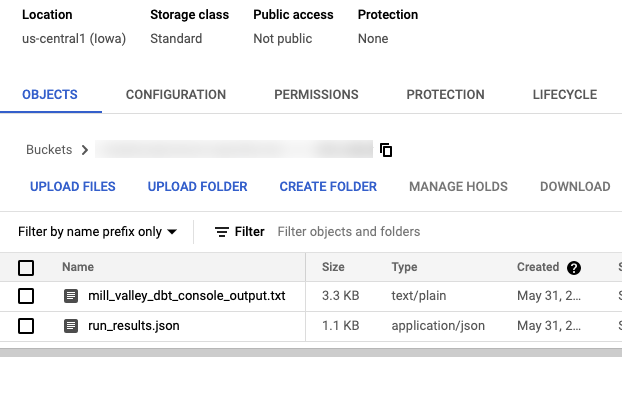
And of course, I have the artifacts in Cloud Storage after the dbt run has concluded.
You can also create and execute Cloud Run Jobs with Cloud Workflows - another amazing tool - but I'll leave that for another post.
I probably glossed over a few details, so please reach out if you have any questions.
- Next: Cross domain tracking in Google Analytics 4
- Previous: New blog platform